膨大な量のデータを処理するには、ハードウェアアクセラレータを使用します。ハードウェアアクセラレータは、複雑なAIモデルを非常に高速に実行するのに役立ちます。これらのデバイスは、AIと機械学習のジョブをより容易かつ強力にします。ここ数年で、多くの新しいタイプのAIハードウェアが登場しています。現在、企業はさまざまなAIジョブ向けに専用のプラットフォームを開発しています。
Microsoft は HoloLens ヘッドセット用の AI チップを開発中です。
Google はクラウド内の AI に Tensor Processing Unit を使用します。
AmazonはAlexa用のAIチップを開発中。
AppleはSiriとFaceID用のAIプロセッサを開発。
テスラは自動運転車用の AI プロセッサを開発しています。
AI ソフトウェアがよりスマートになるにつれて、ハードウェアもそれに追いつくように変化します。
主要なポイント(要点)
ハードウェアアクセラレータはAIタスクを高速化し、大量のデータを素早く処理するのに役立ちます。
GPUやASICなど、様々なアクセラレータがあります。それぞれ特定のAIジョブ向けに作られています。ニーズに合ったものを選んでください。
ハードウェアアクセラレータは消費電力が少なく、コストも抑えられます。これにより、AIプロジェクトの効率が向上します。
並列計算は、大きなタスクを小さなタスクに分割します。これらの小さなジョブは同時に実行され、AIのパフォーマンスを向上させます。
将来、AIハードウェアには専用のチップとエッジコンピューティングが搭載されるようになり、処理速度と効率がさらに向上するでしょう。
AIにおけるハードウェアアクセラレータ
スピードと効率
大量のデータを扱うには高速なツールが必要です AIハードウェアアクセラレータは、データ処理を大幅に高速化します。これらのデバイスは通常のCPUよりも高速です。機械学習や AI 仕事が早く進みます。
主な種類 ai アクセラレータは次のとおりです。
グラフィックスプロセッシングユニット(GPU)
テンソルプロセッシングユニット(TPU)
特定用途向け集積回路 (ASIC)
中央処理装置 (CPU)
フィールド プログラマブル ゲート アレイ (FPGA)
GPUは小さなコアを多数搭載している点で特別なものです。一度に大量の計算を実行できます。これは次のような用途に最適です。 ai 画像認識や言語タスクなどのタスクに最適です。カスタムASICは特定のジョブ向けに開発されており、強力なパフォーマンスと省電力を実現します。これらのアクセラレータは、モデルのトレーニングを高速化し、消費電力を削減するのに役立ちます。
ヒント: ハードウェアアクセラレータを使用すると、 ai 数日ではなく数時間でモデルを作成します。
ベンチマークはこれらのアクセラレータの速度を示します。例えば、GPUは約15,700GFLOPSに達します。TPUは1秒あたり最大275,000回のINT8演算を実行できます。MLPerfトレーニングベンチマークなどのツールを使えば、異なるアクセラレータの性能を比較できます。 ai アクセラレータは機能します。どれが自分に最適か確認できます ai 。
ディープラーニングの実現
ディープラーニングモデルは数十億のパラメータを持つことがあります。強力な ai これらのモデルを学習させるには、アクセラレータが必要です。FPGA、GPU、ASICなどのハードウェアアクセラレータがこれを可能にします。これらのアクセラレータはメモリ使用量を削減し、処理速度を向上させます。つまり、メモリの問題を起こさずに、より大きなモデルを学習できるということです。
さまざまなアクセラレータがディープラーニングにどのように役立つかを以下に示します。
加速器 | どのように役立つか |
|---|---|
GPU | 複雑なニューラルネットワークには多数のプロセッサが使用されます。これにより、ディープラーニングモデルのトレーニング速度が向上します。 |
ASIC | 特別な用途のために作られた ai ジョブ。トレーニングが高速化され、消費電力も削減されます。 |
FPGA | ニーズに合わせて設計を変更できます。より効率的にしたり、大規模なモデルを扱えるようにしたりできます。 |
高帯域幅のメモリシステムも搭載されています。これらのシステムはデータの滞留を防ぎ、 ai モデルはスムーズに動作します。複数のGPUを使用すれば、さらに大規模なモデルを学習できます。InfiniBandやNVLinkなどの技術は、デバイス間でデータを高速に転送するのに役立ちます。これにより、 ai 仕事の規模が大きくなり、効率も上がります。
データの局所性を考慮した方法を使用すると、データをより速く取得できます。
トレーニング中のコミュニケーション量を減らすことができます。
演算ユニットを改善して速度を上げることができます。
これらのツールを使用すると、高度なディープラーニングモデルをトレーニングできます。 ai 音声認識、自動運転、医療診断などの分野では、ハードウェアアクセラレータが精度と速度の向上に貢献しています。 ai.
AIアクセラレータの種類

数多くのAIアクセラレータからお選びいただけます。それぞれが特定の用途向けに設計されており、特定のAIタスクに適したものもあります。主な種類はGPU、NPU、FPGA、ASICです。これらのツールは、機械学習をより高速かつ高品質に実行するのに役立ちます。
ハードウェア アクセラレータ | 他社とのちがい | 優位性 | 製品制限 |
|---|---|---|---|
GPU | 多数のコアを連携させて使用します。 | 数学的な仕事や高速なデータ作業に最適です。 | 一部のジョブでは ASIC ほど適していません。 |
NPU | ニューラル ネットワーク用に構築されています。 | ディープラーニングに非常に適しており、エネルギーを節約します。 | FPGAほど柔軟ではありません。 |
FPGA | 動作方法を変更できます。 | 特殊な作業に合わせてカスタマイズし、すぐに結果を得ることができます。 | セットアップとプログラミングが難しくなります。 |
ASIC | 1 つの仕事のためだけに作られました。 | 非常に高速で、その作業に必要な電力もほとんど消費しません。 | 他のジョブに使用することはできません。 |
GPU
GPUはAIジョブで広く利用されています。同時に多くの処理を実行できるため、大量のデータを高速に処理できます。GPUはディープラーニングや素早い答えの発見に最適です。モデルのトレーニングを高速化し、画像認識などの処理が可能になります。また、機械学習で使用される数学的な処理にも役立ちます。
GPU は一度に多数のデータを処理します。
トレーニングが高速化され、AI のパワーが強化されます。
NPU
NPUはニューラルネットワーク向けに開発されており、多くのAI製品に搭載されています。NPUは高速で、ディープラーニングに必要な電力を節約します。自動運転車やロボットなど、素早い回答が求められる用途に適しています。NPUはセンサーデータ、音声、画像の処理にも役立ちます。
NPU により AI システムの動作が向上します。
迅速な回答やメディアの仕事に役立ちます。
FPGA
FPGAは、ニーズに合わせて動作方法を変更できます。購入後、新しいジョブ用に設定することも可能です。FPGAは、迅速な結果と高い処理能力が求められるジョブに適しています。また、制御が必要な特殊なAIジョブにも使用できます。
FPGA を使用すると、AI 用のハードウェアを設計できます。
必要に応じて新しいジョブに変更できます。
ASIC
ASICは特定のAIジョブ向けに作られています。最高速度と省電力性を提供します。音声やデータセンターの作業など、変化のないジョブに最適です。高速で消費電力も少ないですが、他の用途には使用できません。
ASIC は特殊な AI ジョブ用に作られています。
すぐに回答が得られ、エネルギーを節約できます。
ヒント:AIアクセラレータを選ぶ際は、AIジョブと、どの程度の変更が必要かを検討してください。それぞれのタイプは、それぞれ異なるジョブに適しています。
AIワークロード最適化
トレーニングと推論
AIには主に2つのステップがあります。1つ目は学習です。学習には多くのコンピュータパワーが必要です。多くの数学の問題を何度も繰り返し解くことになります。強力なAIアクセラレータは、こうした難しい作業を支援します。2つ目のステップは推論です。推論とは、AIが新しいデータを見て選択を行うことです。このステップではそれほど多くのハードウェアは必要ありません。アクセラレータ1つ、あるいはCPU1つでも構いません。
注:推論を高速化することで、大幅なコスト削減につながります。不正チェックや提案機能など、多くのAIツールでは、迅速かつスマートな推論が求められます。
選択するハードウェアは、業務内容によって異なります。以下に例をいくつか挙げます。
シナリオ | トレーニング用ハードウェア | 推論ハードウェア |
|---|---|---|
売上予測エンジン | CPU | CPU |
画像分類モデル | GPU | 必要に応じてCPUまたはGPU |
推論の方法は様々です。モデルの規模、使用場所、そしてどれだけ速く答えを得たいかによって異なります。設定、調整、配置、大規模なモデルでの作業、あるいはエッジでの使用など、様々な作業が必要になるかもしれません。優れた推論システムを構築するには、多くの場合、専門家の協力が必要です。新しいハードウェアだけで済むわけではありません。
並列計算技術
並列計算を利用することで、AIの性能を向上させることができます。これは、大きなジョブを小さなジョブに分割し、同時に実行することを意味します。AIアクセラレータは、これを様々な方法で実現します。
並列処理は、ジョブを複数のCPUまたはGPUに分割します。これにより、AIはより高速かつ効率的に動作します。
データ並列処理はデータを細分化します。各アクセラレータはそれぞれ1つのデータに対して処理を行います。そして、すべての結果をまとめます。
モデル並列処理によりAIモデルが分割され、異なるアクセラレータが同時に異なる部分で動作します。
これらの方法により、AIアプリの動作が高速化されます。例えば、GPUとNPUは並列処理を利用してディープラーニングを支援し、消費電力を節約します。これにより、より優れた結果が得られ、速度を低下させることなく、より大規模なAIジョブを処理できるようになります。
アクセラレータの比較

パフォーマンスと効率性
あなたが欲しい AIプロジェクトを高速化 消費電力も少なくなります。異なるハードウェアを比較する際には、タスクの完了速度と消費電力に注目します。アクセラレータによっては、AIモデルのトレーニングを他のアクセラレータよりもはるかに高速に実行できるものもあります。例えば、最新のベンチマーク結果によると、NVIDIA B300はわずか9.59分でトレーニングを完了できます。AMD Instinct MI355Xは、旧モデルと比較して最大2.8倍高速です。これらのデバイスの性能比較は、以下の表をご覧ください。
GPUモデル | トレーニング時間(分) | パフォーマンスの向上 |
|---|---|---|
AMD Instinct MI355X | 10.18 | 最大 2.8 倍高速 |
NVIDIA B200 | 9.85 | 無し |
NVIDIA B300 | 9.59 | 無し |
AMD Instinct MI300X | 28 | 無し |
AMD Instinct MI325X | 〜20 | 無し |
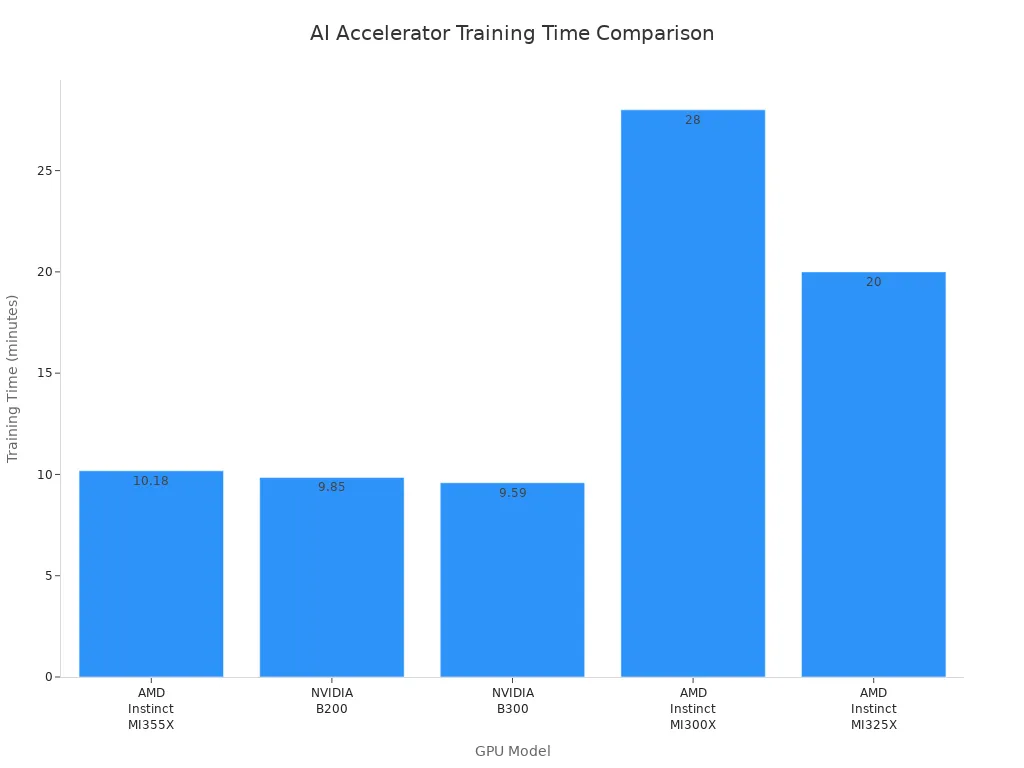
これらの数値を参考に、ニーズに最適なAIハードウェアをお選びください。トレーニングが高速化すれば、より多くのアイデアを試し、より早く成果を得ることができます。また、高いパフォーマンスはエネルギーとコストの節約にもつながります。適切なハードウェアを選択することで、速度と効率の両方を向上させることができます。
展開シナリオ
AIはクラウドやエッジなど、様々な場所で活用できます。それぞれの場所にはメリットと限界があります。エッジでAIを運用すれば、ネットワーク遅延を削減できます。また、データのプライバシーも確保でき、コストも削減できます。例えば、エッジAIはネットワークの待機時間を50~200ミリ秒削減できます。さらに、データコストも最大80%削減できます。一方、クラウドでは遅延が大きくなり、データ使用量が増える可能性があります。
エッジ AI とクラウド AI を比較するのに役立つ表を以下に示します。
側面 | エッジAIのメリット | クラウドAIの制限 |
|---|---|---|
レイテンシ | 50~200ミリ秒のネットワーク往復遅延を排除 | データ転送による高遅延 |
Data Privacy | 機密データをローカルで処理する | 外部サーバーへのデータ転送が必要 |
帯域幅の最適化 | データをローカルで処理することで帯域幅を削減 | データ転送のための高帯域幅使用 |
コストの削減 | データ転送コストを60~80%削減 | 帯域幅による運用コストの増加 |
AIをどこで実行したいかを検討する必要があります。迅速な回答とプライバシーが必要な場合は、エッジAIが最適です。大規模なジョブに高い処理能力が必要な場合は、クラウドAIの方が適しているかもしれません。適切な選択は、プロジェクトと目標によって異なります。
課題と傾向
統合の問題
AIでハードウェアアクセラレータを使用すると、問題が発生する可能性があります。ハードウェアとソフトウェアが適切に連携していることを確認する必要があります。両者が適合していないと、AIモデルの動作が遅くなる可能性があります。また、消費電力とメモリ使用量にも注意が必要です。これは、大規模なAIモデルでは非常に重要です。場合によっては、新しいAI手法に合わせて設定を変更する必要があることもあります。以下の表に、よくある問題をいくつか示します。
課題 | 詳細説明 |
|---|---|
ハードウェアとソフトウェアを組み合わせることで最高の速度を実現します。 | |
資源効率 | 大規模な AI モデルに使用するエネルギーとメモリを削減します。 |
多角的な視点で挑む | 新しい AI のアイデアに合わせてシステムを変更できることを確認します。 |
これらの問題を解決するために、新しいソフトウェアを活用することができます。例えば、SNAXを使えば、異なるアクセラレータを簡単に接続できます。シンプルなレイヤーが提供されるため、AIの作業に集中できます。SNAX-MLIRは、メモリとデータの使用効率を向上させ、AIシステムの高速化を実現します。
ヒント: SNAX などのツールを使用すると、AI の成長に合わせて新しいアクセラレータを追加したり、設定を変更したりできます。
AIハードウェアの未来
AIハードウェアに大きな変化が訪れています。企業は現在、特定のジョブ向けに特別なAIチップを開発しています。これらのチップは、AIの高速化と省電力化に貢献します。また、GPU、FPGA、ASICといった異なるプロセッサを組み合わせたシステムも増えていくでしょう。これはヘテロジニアスコンピューティングと呼ばれ、AIの各ジョブで最適な結果を得るのに役立ちます。
今後の傾向は次のとおりです。
NPU や TPU などのカスタム AI チップがより多く使用されるようになります。
エッジコンピューティングは、データを取得した場所の近くで処理することを可能にします。これにより、遅延が低減され、データのプライバシーが保護されます。
ニューロモルフィック コンピューティングは、脳のような設計を使用してエネルギーを節約し、AI を改善します。
量子コンピューティングは非常に難しい問題を解決できるかもしれませんが、解決すべき問題がまだたくさん残っています。
専門家は、AIハードウェア市場が大きく成長すると予測しています。2024年には165億5000万ドル規模に達し、2029年には527億6000万ドルに達する可能性があります。これは、毎年約26%の成長を意味します。
注: AI ハードウェアが向上するにつれて、AI プロジェクトをより高速かつ強力にする方法が増えます。
AIにおけるハードウェアアクセラレータには、多くのメリットがあります。これらのツールは作業を高速化し、即座に意思決定を可能にします。また、使用することでコストも削減できます。以下の表で簡単に概要をご覧ください。
商品説明 | 詳細説明 |
|---|---|
強化されたパフォーマンス | AIを高速化し、より良く機能させる |
エネルギー効率 | AIジョブの消費電力を削減 |
拡張性 | AIが大きくなるにつれて成長できる |
AIジョブに最適なアクセラレータを選びましょう。新しいチップ設計と省電力化の手法は、AIの将来的な動作に変化をもたらすでしょう。
FAQ
AIにおけるハードウェアアクセラレータとは何ですか?
ハードウェアアクセラレータは特殊なチップまたはデバイスです。AIタスクを高速化するために使用し、コンピューターがビッグデータや複雑なモデルを処理できるようにすることで、処理速度を低下させることなく作業できます。
なぜ異なるタイプの AI アクセラレータが必要なのでしょうか?
AIジョブはそれぞれ異なるため、それぞれ異なるアクセラレータが必要です。トレーニングに最適なものもあれば、素早い回答に最適なものもあります。最適なアクセラレータを選択することで、最高の速度と省電力を実現できます。
ハードウェア アクセラレータを自宅で使用できますか?
はい、自宅でアクセラレータを使うことは可能です。多くのノートパソコンやデスクトップパソコンにはGPUが搭載されており、学習、ゲーム、小規模プロジェクトなどのAIプログラムを実行するのに役立ちます。
ハードウェア アクセラレータはどのようにしてエネルギーを節約するのでしょうか?
ハードウェアアクセラレータはAIタスクを高速に処理します。通常のCPUよりも消費電力が少ないため、エネルギーを節約し、電気代を削減できます。
AIハードウェアの将来はどうなるのでしょうか?
AI用のカスタムチップが今後ますます増えるでしょう。これにより、デバイスはよりスマートで高速になります。ニューロモルフィックチップや量子チップといった新しい設計は、AIの活用方法を大きく変えるでしょう。